This article is the second in a series of kdb insight articles. Read part one, ‘Getting Started with kdb Insights’ here.
Introduction
PyKX is the latest iteration of python/kdb+ interfaces that aim to provide Python users with the ability to interact and utilize the power of kdb for real-time and historical analytics.
It helps Python-using data scientists and quants interrogate and analyze data sets that can be larger, faster, or in real-time, helping them run key time-series data ingestion and analytics operations including as-of joins and time-series bucketing, where kdb excels.
For modelers, PyKX helps speed up and efficiently perform compute-intensive models such as machine learning, back-testing, simulation, and optimization. In all cases, Python users can immediately get analytics speed increases of up to 100x and take their research applications to production workloads faster.
PyKX takes a Python-first approach and utilizes a shared memory space with q to provide faster interaction between the two languages.
In this article, we will look at some of the key features of PyKX and how it can streamline and optimize interactions between the technologies.
Installation
PyKX can be installed using pip:

And imported into your python session:

Required dependencies will be automatically installed by pip.
Python version 3.7 to 3.10 are currently supported.
Interface Iterations
PyKX builds and improves on a number of previous iterations of python/kdb+ interfaces:
- pyQ: This provided a method for bringing python and q into the same process but required a special binary, which posed a barrier to full adoption for python developers. Instead, PyKX runs from the standard python binary so it can integrate fully with other packages.
- QPython: This provided a q client for python to query q data over IPC. While this is a common use case, it had the added overhead of always converting data into python objects. Instead, PyKX provides functionality to query q servers but does not force a conversion to python types. This provides extra flexibility and increases performance.
- EmbedPy: This was primarily for q developers wishing to leverage python functionality, but it offered no method for accessing q/kdb objects from python. Instead, PyKX focuses on a Python-first approach to bring the power of kdb+ to python users. Objects can be converted to python or q objects, often with zero copy for numpy/pandas.
PyKX Objects
PyKX objects are the fundamental building blocks of the PyKX interface. These are C representations of q/kdb objects that live in the q memory space. This allows the objects to be queried and interacted with in q without any overhead from converting to python objects.
PyKX objects can be generated a number of ways:
- Converting a python object to a PyKX object
- Evaluating q code through the pykx.q interface
- Fetching a named entity from q’s memory
- Querying a q process over IPC
Evaluating q code through the pykx.q interface
Users familiar with q can execute q code with the pykx.q interface to create PyKX objects:

For users who are not as familiar with writing q code, a number of q functions are exposed under pykx.q, allowing python developers to easily access built-in q functionality. This can grant python users access to the power of q without requiring specific knowledge of the language. Here’s an example, loading a kdb+ table called “trades” from disk using the “kx.q.get” function:
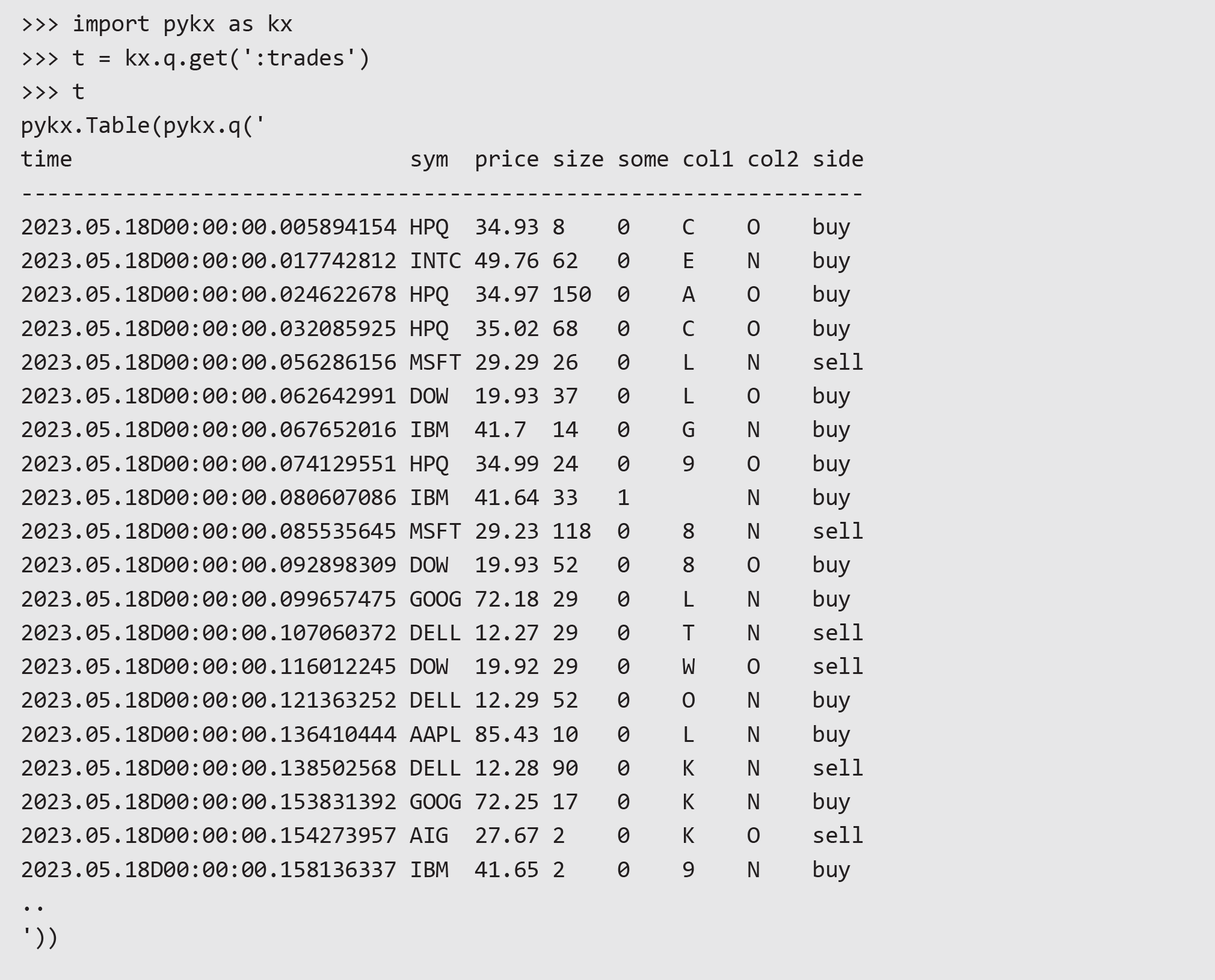
This table is loaded into memory and can be inspected in a pythonic way:
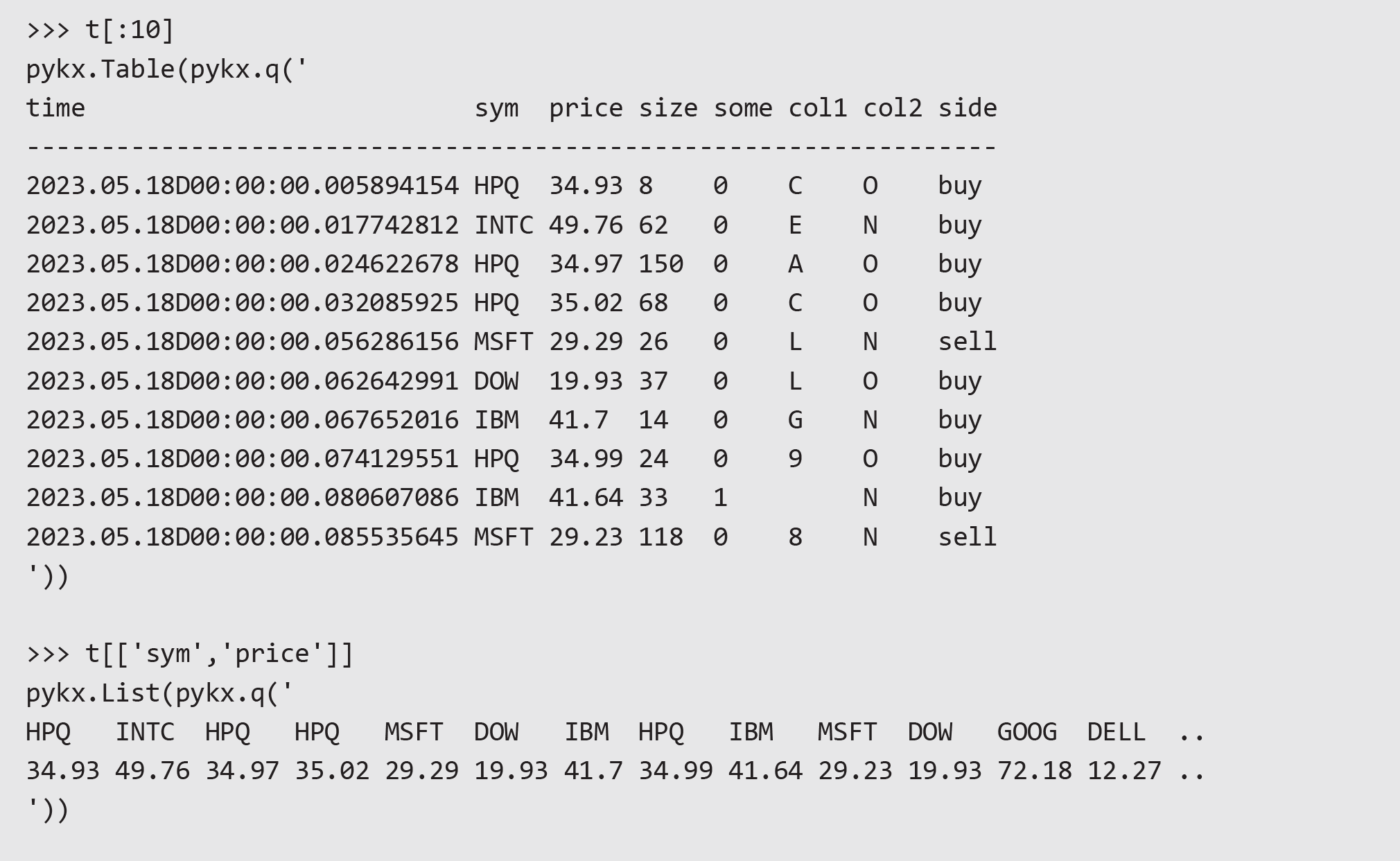
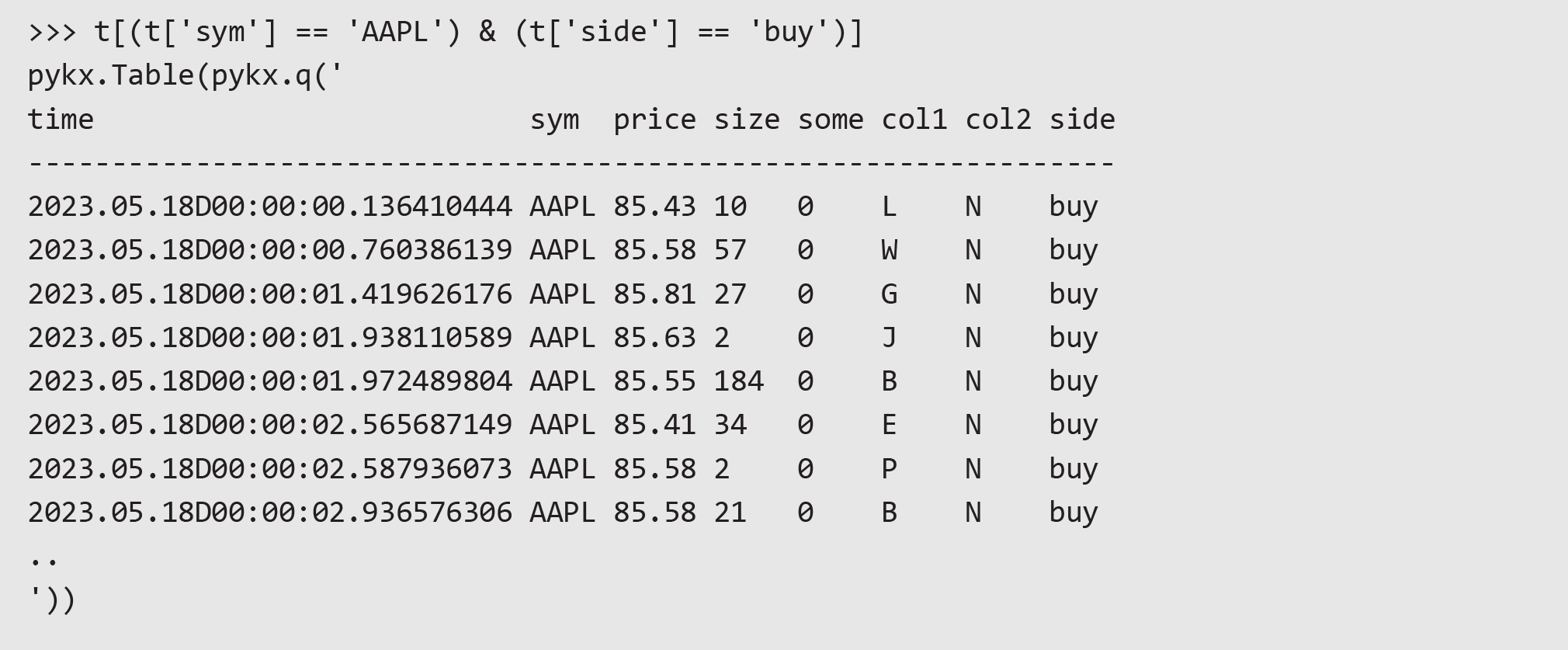
The pandas API allows interaction with these objects as with a dataframe. Here’s an example of filtering on sym and side:
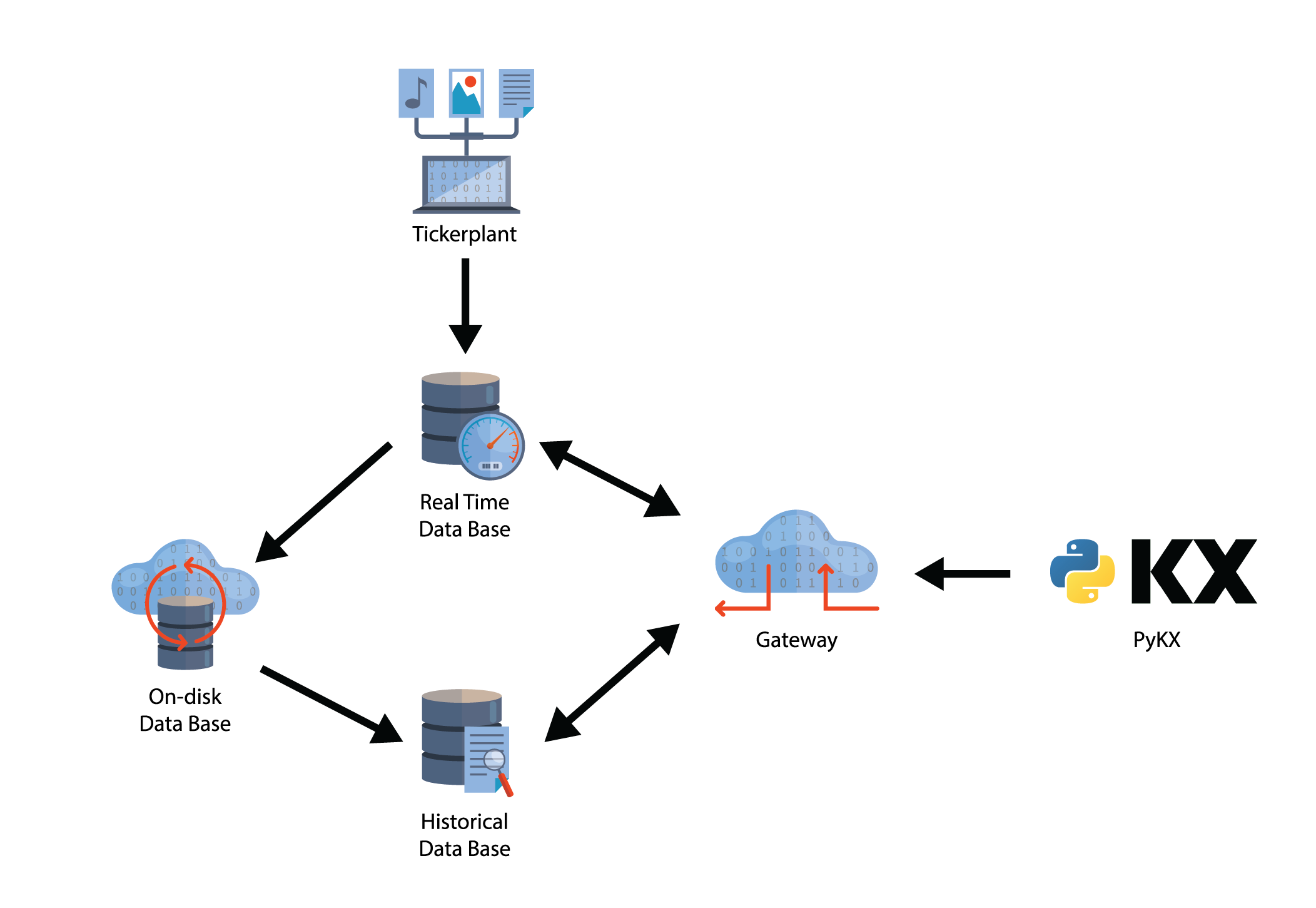
Querying a q process over IPC
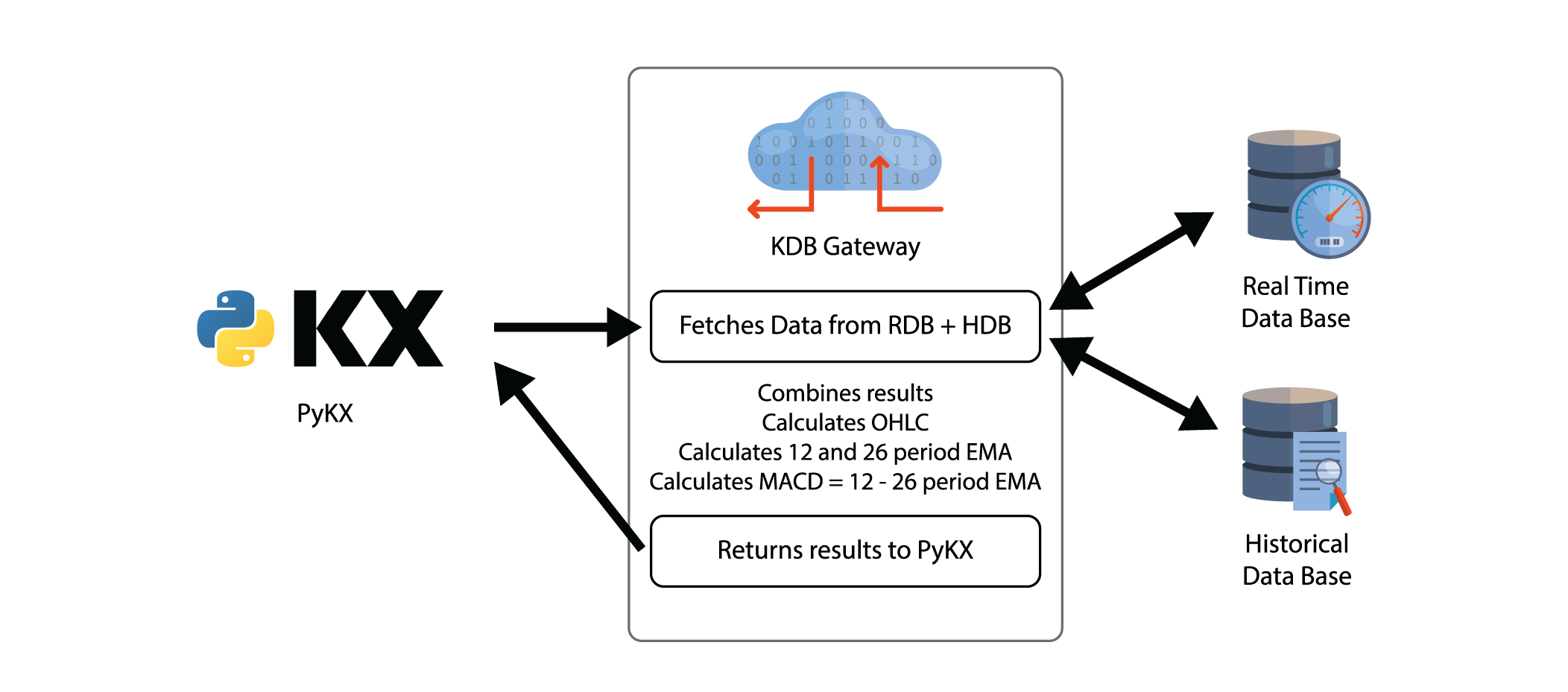
A key aspect of PyKX is the ability to interact with q processes over IPC. This allows PyKX processes to connect directly to real-time and historical databases or gateways to retrieve data. Data pulled into the session is stored as a PyKX object to avoid a costly conversion into Python types.
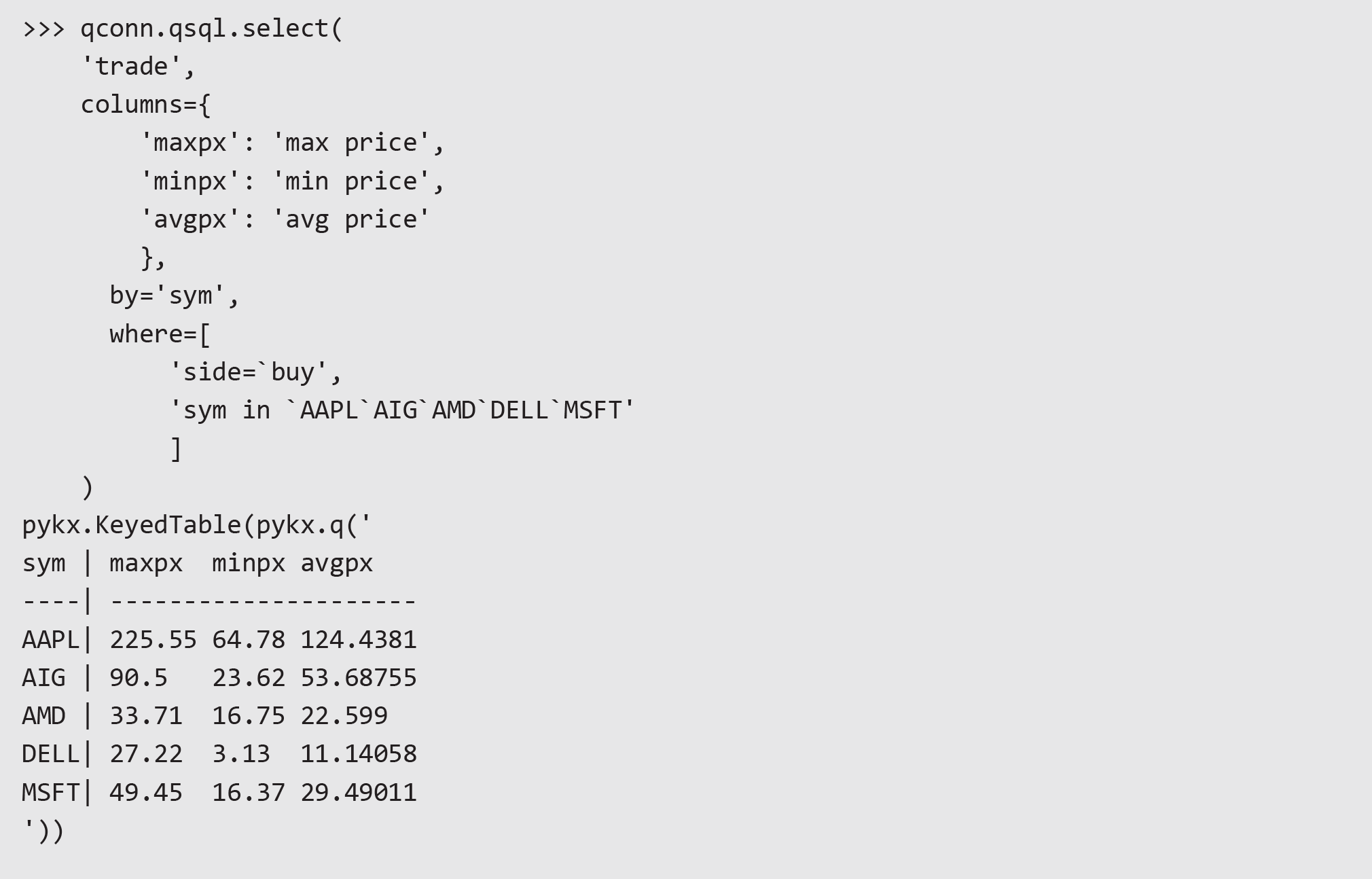
PyKX exposes a qSQL API for querying data over IPC and in-memory. We can use this to run select, exec, update, and delete queries using a pythonic syntax:
A key aspect of PyKX is the ability to interact with q processes over IPC. This allows PyKX processes to connect directly to real-time and historical databases or gateways to retrieve data. Data pulled into the session is stored as a PyKX object to avoid a costly conversion into Python types.
PyKX exposes a qSQL API for querying data over IPC and in-memory. We can use this to run select, exec, update, and delete queries using a pythonic syntax:

To open a synchronous IPC connection to a q process, we can use the pykx.SyncQConnection class:

Then we can create and run our query using the following parameters:
More complex queries can be performed with a little additional q knowledge. For example, bucketing trade data into 30-minute periods and calculating the volume weighted average price:
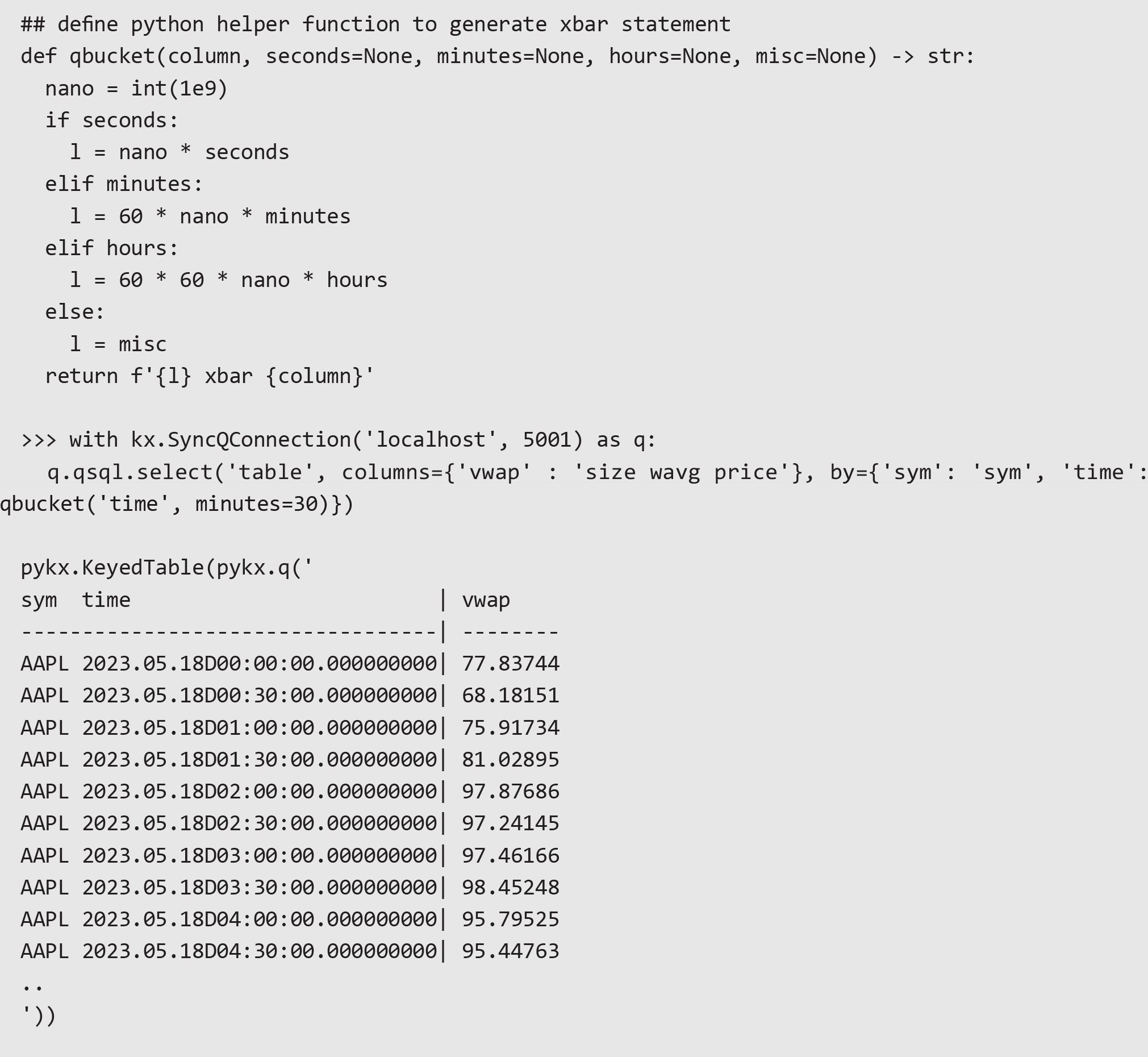
Performance Advantages
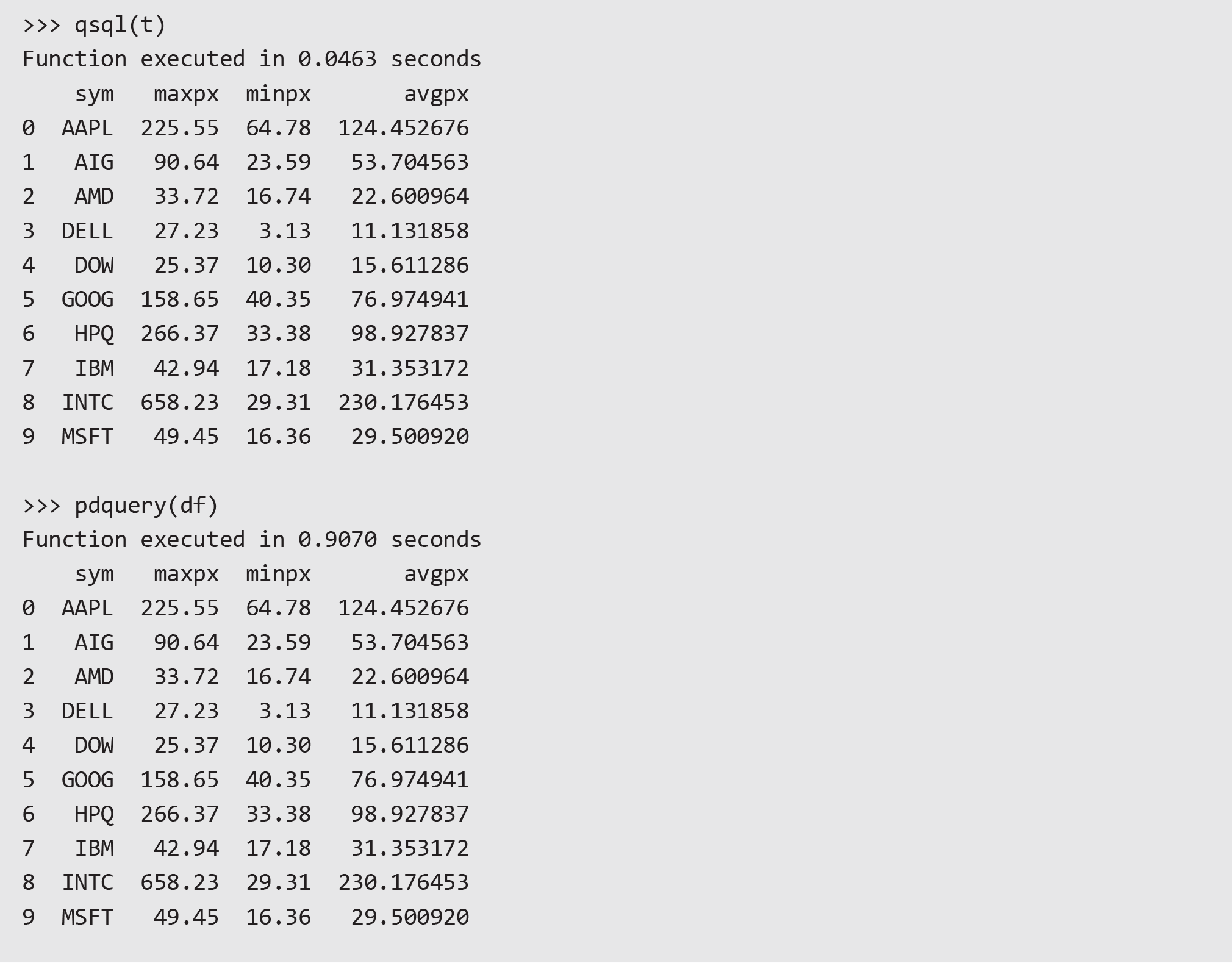
There are significant performance advantages to using qSQL for data aggregation. We looked at a simple example of calculating max, min, and average price per symbol on a 10m row dataset loaded into memory. The final result was returned as a pandas dataframe:

Both queries return the same results, however the performance difference using qSQL is dramatic—we can see ~20x speed-up compared to using pandas:
Using q functions from python
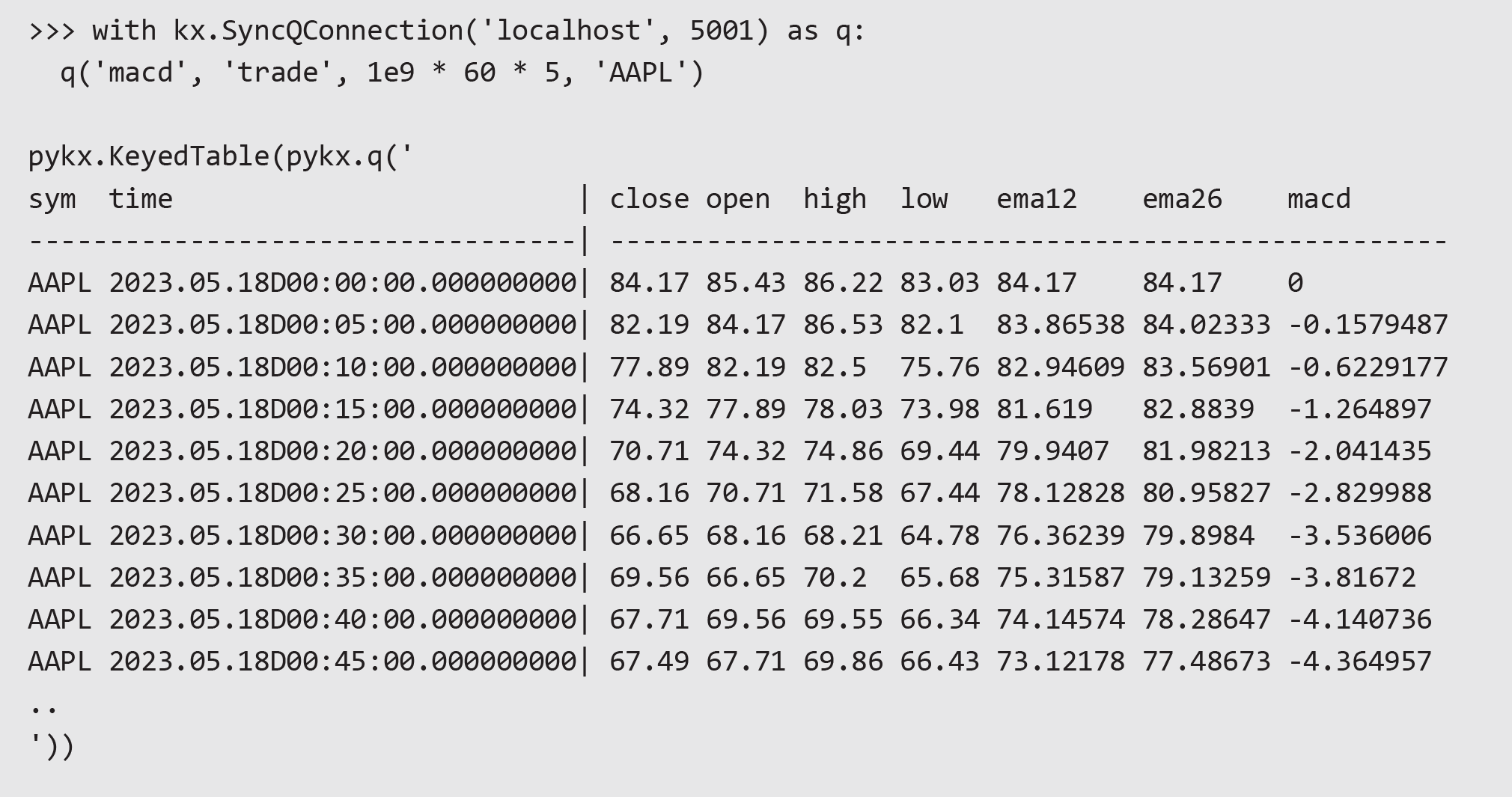
When interacting with a mature q/kdb+ system there are often functions that have been written and optimized in q, which we can take advantage of.
We defined an example function, macd, on an external q process. This function takes three inputs: the table name, the interval length in nanoseconds, and the symbol. We can execute the function on the external process with the following syntax:
Converting PyKX objects to Python
We can easily convert our PyKX objects back into python/pandas/numpy objects to utilize further python processing capabilities. This is supported through the .py() / .pd() / .np() functions. The .pd and .np conversions should be preferred as these avoid copying where possible.
We looked at how we could utilize this functionality to create a visualization using the python Plotly library. Using our ‘macd’ function as before, we can fetch and store the data locally:

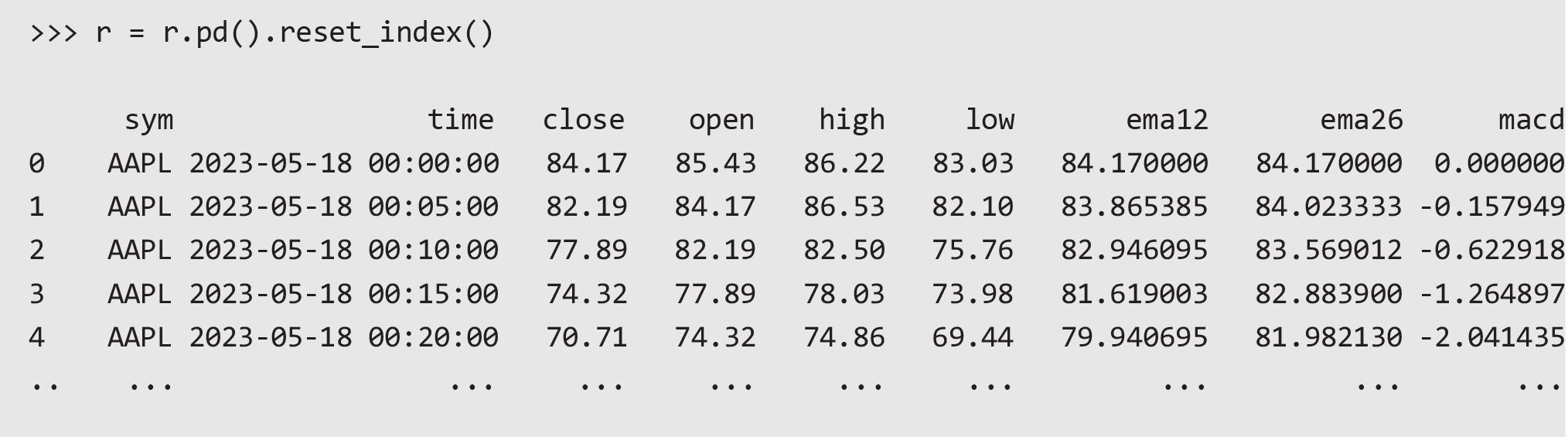
Then we can convert to a pandas dataframe and unkey/reset the index:
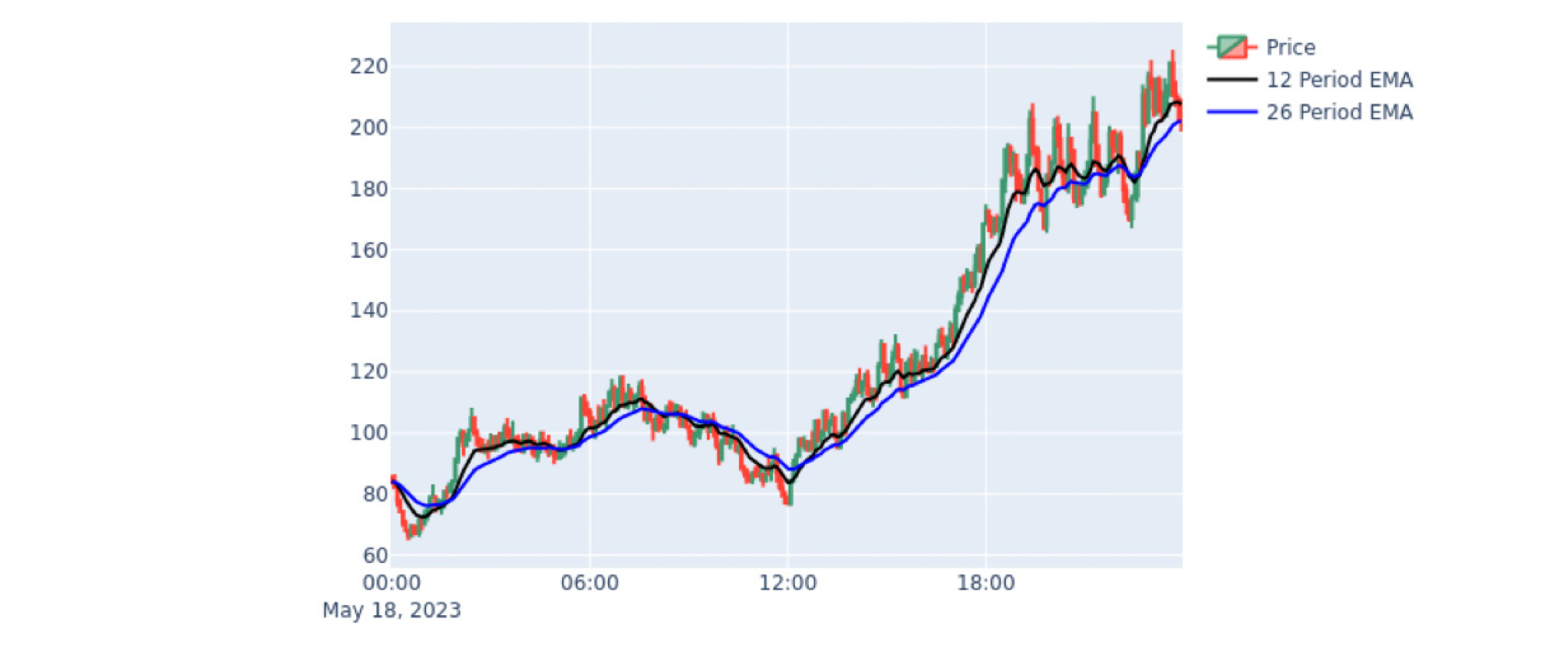
It is now easy to use the Plotly library to create a candlestick chart and overlay two line charts:

Conclusion
This article aimed to give a flavor of the versatility of PyKX, and how it opens up the performance and vector-based analytical capabilities for a time-series data set, to python users who have less familiarity with q.
By building on previous incarnations, PyKX combines the flexibility of working within python and q in a seamless manner, with efficient management of in-memory objects, to deliver the benefits of working with a kdb+ system to the broader python-literate analytics community.
We have also shown how a python user can easily utilize the processing power and efficiency of q/kdb+, while retaining the flexibility of the full python ecosystem of packages.
In our opinion, PyKX is a major step forward and will support the ongoing drive to democratize access to the kdb+ system, beyond the realm of q experts.
Authors

