Introduction
kdb Insights brings the powerful kdb engine to data scientists and engineers with full support for Docker and Kubernetes, and native integration with industry-standard programming languages.
Fully cloud-enabled to operate on AWS, Azure, Google Cloud Platform, and on-prem private-cloud environments, kdb Insights allows you to harness the power of kdb within your cloud environment. It also provides more open integration with cloud-native analytics stacks, to enable you to take your machine learning operations pipelines to the next level.
In this article, we look at a first installation of kdb insights to get you up and running. We’ll use a stream processor as an example.
kdb Insights is composed of the following:
- kdb Insights core – which amounts to kdb+ in the cloud.
- kdb Insights microservices – cloud-native microservices that allow legacy systems to be migrated to the cloud, or additional functionality to be added to existing systems.
- PyKX – an interface between python and q/kdb+.
Note: kdb insights is evolving rapidly. This article is based on documentation v1.4.
What’s New?
- Architecture
- Micro services-based approach.
- The Stream Processor is one of the new features of kdb Insights. It is a micro service that can be compared to the tickerplant commonly seen in kdb+ tick architecture. It offers similar functionalities, with many additional new benefits powered directly by kdb Insights (further detailed below).
- Libraries
- Kurl – Communicates with other cloud services.
- Logging – Allows logging to cloud logging services.
- SQL – Supports ANSI SQL, users do not necessarily need knowledge of q language.
- ml is the new KX Python library supporting PyKX, which is an extremely powerful tool to integrate Python code with kdb+ code. KX testing shows it even has the ability to speed up the pandas data frame model. Other features include machine learning capabilities that can be integrated within kdb Insights.
- See link for more.
- Features
- Native support for reading from object storage.
- Support for ANSI SQL.
- REST services to interface with other cloud services.
Being natively cloud-based, kdb Insights can be used on multiple cloud-based services such as Google Cloud, Azure, and AWS. The benefits to being cloud-based are endless, some of the more obvious being cloud’s elasticity, scalability, cloud security, and ease of onboarding/set up.
Installation Considerations
As with a standard kdb+ binary, kdb Insights Core requires a valid license file to run. This installation guide assumes a valid license file is present at $HOME/qlic and the environment variable QLIC is set to this location.
Before installation of kdb Insights Core the following prerequisite libraries must be installed:
- so at least version 7.31.
- so which should be openssl1.1 compatible.
kdb Insights Core is delivered as a ZIP (l64.zip) inside a TGZ archive and contains the q binary and the kdb Insights Core libraries:

To install in your home directory, navigate to the download location of the zip file and run the following commands:

If successful, a q session can be started with the following command:

First Usage
- Introduction to Stream Processor
- The kdb Insights Stream Processor is a real-time data processing micro service with resemblance to the kdb+ tick architecture. It enables the capture, processing, analysis, and save down of data.
- As with the kdb+ tickerplant, the Stream Processor worker process is responsible for capturing, reading/writing, manipulating/filtering, and saving down the data.
- Example of Stream Processor
- In our example, a modified version of a randomized TAQ (trade and quote) data generator was used.
- From the codebase, TAQ data is generated through this random data generator with the output fed into kdb Insights.
We set up a function called dataUpdate, which publishes randomized TAQ data to the respective Trade and Quote tables.

This function will be called by .z.ts – the timer function for kdb, every interval (set by \t)

To define the publishing functions and let the function be read, pipelines must be set up with the function .qsp.read.fromCallback.
https://code.kx.com/insights/1.3/api/stream-processor/q/readers.html#qspreadfromcallback
This operator defines both publish functions. Input data will enter one of the two separate pipeline data flows, depending on which function is called.
Each pipeline can only call read.fromCallBack once, and therefore can only define one variable at a time. Set up of two variables such as in our example, trade and quote, requires set up of two pipelines.

The following line will start both pipelines.

To use the data that has been entered, there is a list of functions in kdb Insights. Here we present two examples of ways of using the Writers function.
https://code.kx.com/insights/1.3/api/stream-processor/q/writers.html
With the function .qsp.write.toConsole, the data that was ingested can be displayed to the terminal.
To modify and get statistics from the tables – in this case, the moving average of the price in trade, keyBy can be added and stats functions from kdb Insights to the pipeline can be leveraged.
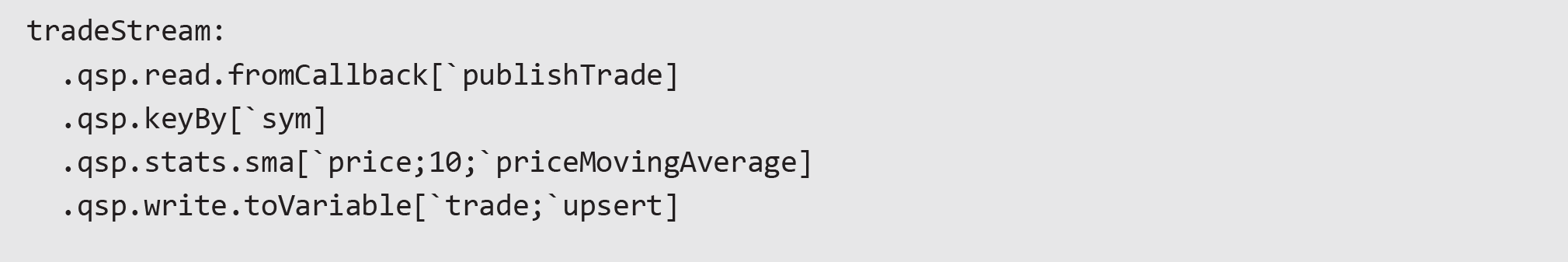
Advantages of Using kdb Insights
- Ease of setup – the codebase that generates quote and trade data are from kdb+. The kdb Insights part of the codebase is easier to read and code. To be able to generate the moving average of price in the trade table and then publish it, an RDB would take a much larger codebase, yet in kdb Insights it was defined in only two lines.
- As the example above shows, the whole process only took about 10 lines to set up a fully functioning tickerplant using kdb Insights. On kdb+, tickerplant set up would have been an entirely different process, and the user would need to define multiple schemas and customize the tickerplant for specific usage.
Conclusion
This article is aimed to show how easy it is to get started with kdb Insights, and it just scratches the surface of what is possible.
With the core technology being kdb+, kdb insights has the benefit of being able to process high volumes of streaming data at the pace needed within the financial industry. With the adoption of cloud, and development of the next generation solution, setting up a scalable system is now easier than ever. The added libraries that allow for kdb Insights to utilize Python and SQL functionality natively make this an even more alluring tool for use in the modern financial industry.
We’ll showcase more capabilities in future articles.
About Us
Treliant is a financial services consulting firm with a strong focus on data, regulation, and digital transformation. We help financial services organizations navigate the complexities of the modern world. Our firm can assist in the following ways:
- Data solutions: We support organizations in leveraging the power of kdb+. We install, develop, and support complex kdb+ environments for fast-paced financial services organizations. We also have broader data capabilities supporting organizations with the efficient build-out of regulatory, risk, and finance platforms.
- Digital transformation: Treliant offers technology enablement to ensure rapid and sustained improvement within your organization.
- Regulatory guidance: Our firm provides guidance and support to financial services organizations on the interpretation and implementation of regulatory changes.
- Risk management: We also help financial services organizations identify and manage the risks associated with large-scale changes, including operational, reputational, and financial risks.
Author
