Many of you will have joined the KX Live conferences in New York and London in September. You will have learned about some of the newer approaches to cloud deployment and access to kdb+ data, which is now being provided through tools such as SQL and Python.
However, regardless of deployment solution or data access method, performance of the core kdb+ engine remains fundamental to any KX installation. As part of our continuing series of blogs to support customers and help kdb+ engineers solve real-world problems, Thomas Smyth shares his experience in how best to introduce parallelism to further optimize performance in the kdb+ environment. (You can read his previous blog post here, on optimizing queries.)
Parallel Processing
Parallel processing is a method of splitting computational tasks into smaller parts that can be executed simultaneously over multiple processor cores. The aim of parallel processing is to reduce overall execution time when compared to sequential execution. Typically, this is reserved for tasks that are computationally or data intensive.
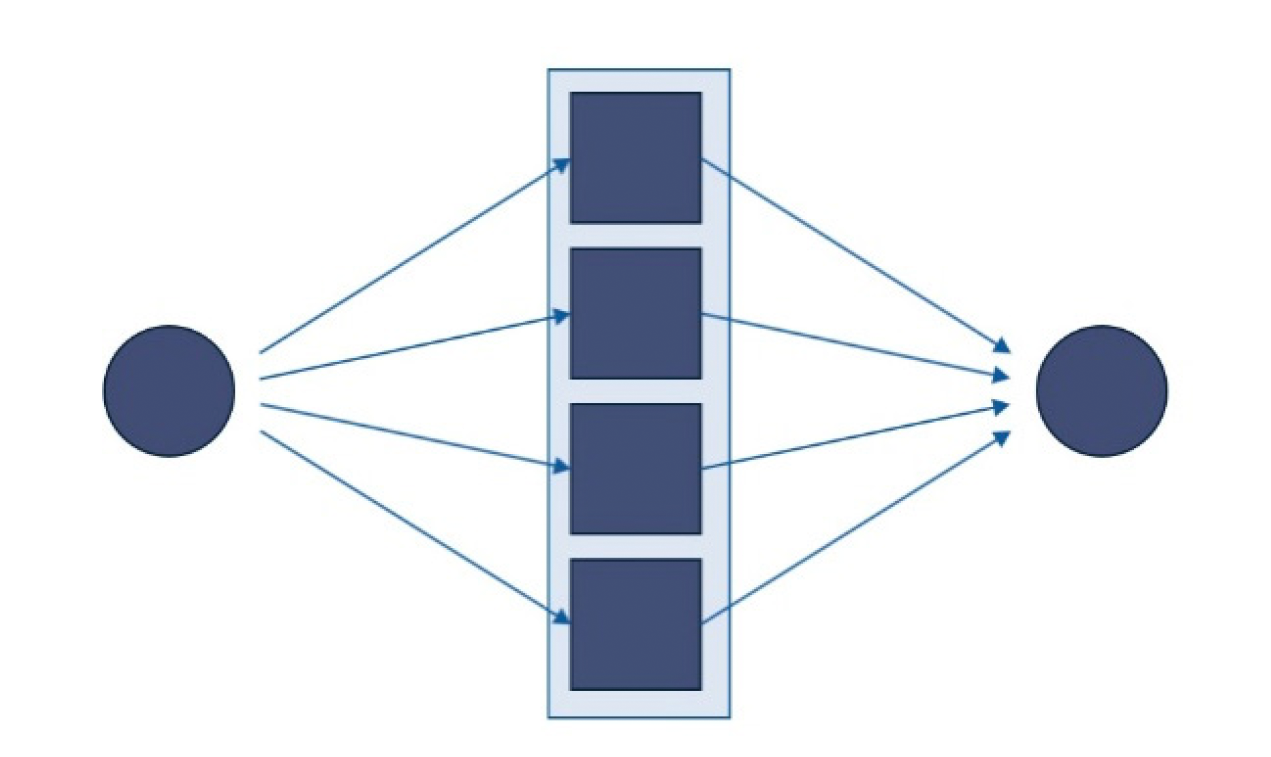
Figure 1: Diagram of parallelization
Kdb+ is by default single-threaded, using a single CPU core. Additional cores may be used by spawning secondary threads, which allows for parallelization. This article aims to give an overview of how to employ parallel processing in kdb+, with consideration given to scenarios that may be unsuitable for parallel processing.
Parallel Processing with Secondary Threads
Secondary threads may be spawned by starting a kdb+ process using the -s n command line flag, where n is the maximum number of threads. The number of available threads may be dynamically adjusted within the process using the system command \s, limited by the value of n. Optimally the number of secondary threads should be greater than or equal to the number of available cores, but the usage of the host may impact this.

Data sent between main and secondary threads undergoes IPC serialization, which introduces overhead. Parallelized operations should therefore, be costly enough to justify this overhead.
When working with secondary threads, operations that involve updating global variables or calling system commands are restricted. These operations may only be performed by the main thread.
Two functions exist in kdb+ that allow secondary threads to be explicitly leveraged – peach (parallel each) and .Q.fc (parallel on cut).
Parallel Each – peach
The function peach is the parallelized version of each but executes operations over secondary threads, if available. When using peach the workload sent to each thread is precalculated and distributed in a “round robin” fashion. If operating on a vector using 2 threads, then the first thread is assigned indices 0, 2, 4, 6, with the second thread assigned indices 1, 3, 4, 7, etc. Essentially this equates to index mod n, where n is the number of threads. Below is an example distribution of a 6-item vector when using 2 and 3 threads.

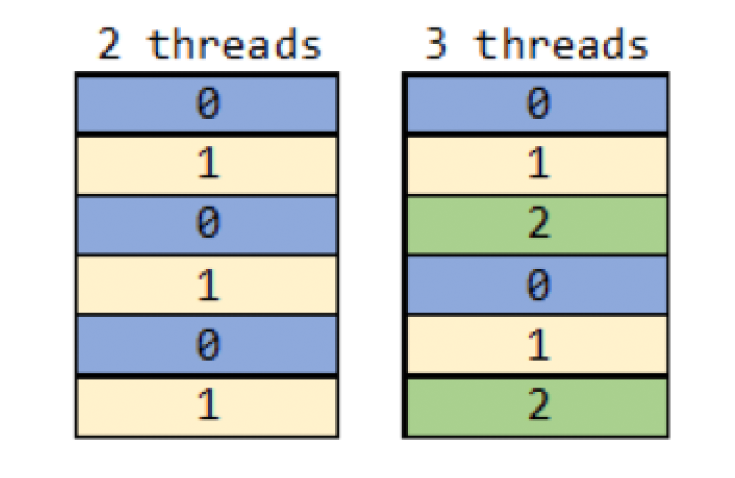
Figure 2: Workload distribution using peach for a 6-item vector over 2 and 3 threads
For best performance, all threads will handle similar workloads. If workloads are distributed unevenly, then it is possible some threads will complete their tasks and remain idle while other threads continue working. It is up to the user to ensure workloads are distributed evenly.
The example below highlights the impact of poor distribution across 2 threads. The execution time of function f is proportional to the integer input. In the first scenario, the vector is arranged into contiguous blocks of identical values, which are distributed evenly among threads when using peach. In the second scenario, the vector is arranged with alternating values and work is distributed unevenly among threads. As a result, the first thread will complete all tasks and remain idle as the second thread remains busy.

Parallel on Cut – .Q.fc
In kdb+, vector operations tend to be more efficient than iterating over a list of atomic values with repeated function calls. The parallelization of vector operations can be handled using .Q.fc which cuts vectors into chunks based on the number of available threads, passing each to a thread for processing. The diagram below shows how a 6-item vector would be split using 2 or 3 threads.
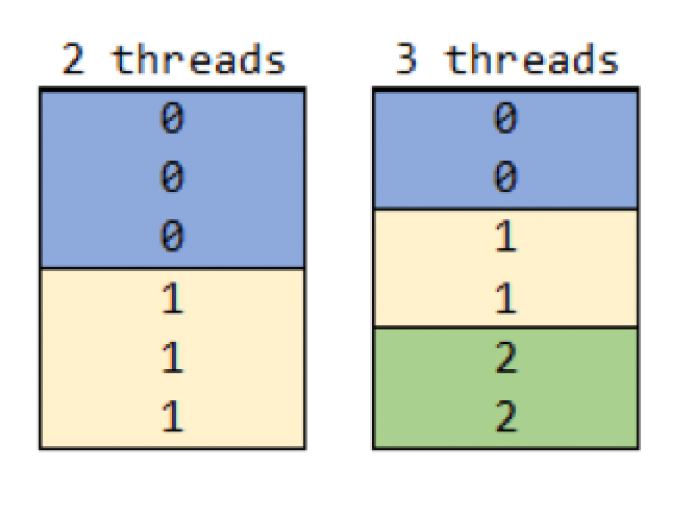
Figure 3: Workload distribution using .Q.fc for a 6-item vector over 2 and 3 threads
Generally, when using a long vector with a vector-optimized function .Q.fc will be more efficient than peach. With peach there is a much larger IPC overhead as each value is passed to a thread separately, and the function is called for each individual value. With .Q.fc there are reduced overhead and function calls, limited to once per thread. The example below compares the performance of both when using vector-optimized sqrt with 4 threads.

Parallelized operations using .Q.fc also require even distribution of the workload by the user to ensure best performance. The example below tests workload distribution using function f with 2 threads. In the first case the vector is split into 2 identical chunks and passed to secondary threads. In the second case the workload is split into uneven chunks, increasing execution time as the second thread has a larger workload.

Map-Reduce
Map-reduce in kdb+ is the method of decomposing an operation on a list into two sub-operations. The map step splits the list into sublists and performs the operation on each to obtain partial results. The reduce step collects and combines partial results to give an overall outcome. Below is the list of operations that support map-reduce.

Map-reduce operations in kdb+ are a natural fit for parallel processing, with aggregations over a partitioned HDB being a prime example of this. If querying across multiple date partitions using a map-reduce supported operation, then separate threads perform the map step with the main thread performing the reduce step.
In the following example, the variance of price per sym is calculated using the var keyword. The operation is mapped to secondary threads when available, resulting in improved performance.

Parallel Processing with Secondary Processes
It is possible for peach to use multiple processes instead of threads for parallelization. This is achieved by starting a q process using -s -n, where -n is a negative integer.

Unlike secondary threads that are created implicitly, secondary processes must be created manually, with a listening port set so that IPC connections can be established.
When using peach with secondary processes, kdb+ evaluates .z.pd to retrieve the handles to the processes. This should be defined as either a list of connection handles with the unique attribute applied or as a function that returns the same list.

When using secondary processes, the workload distribution is not precalculated. Instead, processes are allocated work on completion of previously allocated tasks. Global variables are not shared between the main and secondary processes, and any data required to complete a task must either be passed as an argument or exist on the process already. Additionally, system commands are unrestricted in secondary processes.
One key difference over threads is that processes may be run on remote hosts. This opens the potential to use more memory across multiple hosts rather than requiring all processes to share memory on a single host.
Multi-Threaded Primitives
With the release of kdb+ v4.0, primitives are now implicitly multi-threaded, which is transparent to users. To leverage within-primitive parallelization, vectors must be suitably large. The minimum vector size per thread is in the order of 105 items, but this depends on the primitive. Below this threshold, no improvement will be seen, so it can be advantageous to keep vectors large. Aggregations on grouped values using select … by may not see any improvement. In this case the size of vectors split by the groupings provided may fall below the threshold for implicit parallelization. Consider a trade table containing data for 20 unique sym values with 50,000 rows each, totaling 106 rows. Of the aggregations below, only the first will benefit from parallelization due to the size of the vector. When aggregated by sym, the vector sizes fall under the threshold.

For queries like this, a well-formed expression leveraging peach may give better performance.
Compared to explicit parallelization, within-primitive parallelization has the advantage of working on a single vector at a time, which avoids the issue of scheduling uneven chunks of work with peach. Similarly, when compared to .Q.fc there is no overhead associated with splitting and razing vectors.
Conclusion
The concepts presented in this article give an overview of parallelization in kdb+.
Parallel processing is a great tool for reducing execution time of operations but should not be considered as a cure-all for poorly performing code. Unbalanced workloads and IPC overhead can reduce efficiency when compared to a single-threaded operation. Steps should be taken to optimize code in single-threaded operations before applying multi-threaded solutions.
In the real world of high-frequency trading, code will be more complex than the examples presented here, and solutions involving parallel processing will require greater scrutiny. Before deploying to production servers, the performance of parallelized should be tested thoroughly.
Author
