As part of our new strategic alliance with KX, we continue to build out our kdb+ engineering capabilities to support clients with the delivery of kdb+ orientated projects. The KX platform is used by many financial services to enable them to gain insights from fast moving, trade related data. Speed of access and ability to quickly support decision making is paramount. As a consequence, query performance is a key component of managing any kdb+ environment. In this “blog”, Thomas Smyth shares his experiences in how to optimise the performance of kdb+ queries.
As high-frequency trading continues to accelerate in today’s markets, it’s critical to optimize every trade database query. Programmers new to the kdb+ databases used in this environment often find it challenging to achieve optimal query performance.
Tables within kdb+ can be queried using qSQL, whose form resembles that of conventional SQL. This article aims to give an overview of some methods to optimise qSQL queries, covering:
- Leveraging on-disk partition structure
- Attributes
- Ordering of constraints
- Using minimal columns
- Counting records
Data and Methodology
The performance of the example code in this article is tested using the \ts system command, which returns execution time in milliseconds and space used in bytes. The test dataset contains example trade and quote (TAQ) data, partitioned by date, with 200,000 and 2 million records per day respectively, covering a range of 10 days.
Below is the on-disk hierarchy for this dataset. Partitioned tables have data split by date and saved into separate directories. Tables are found within these directories, with columns splayed (saved to separate files).

Leverage On-Disk Partition Structure
When querying a large partitioned table on-disk, query performance can be greatly improved by leveraging the on-disk structure.
Consider TAQ that is partitioned by date on-disk; by organising the where phrase to filter based first on date, kdb+ can shortcut directly to that directory on disk. If other constraints are placed first, then kdb+ must dive into all date directories first before subsequently filtering by date. The difference in performance can be seen by comparing queries against the partitioned table trade.
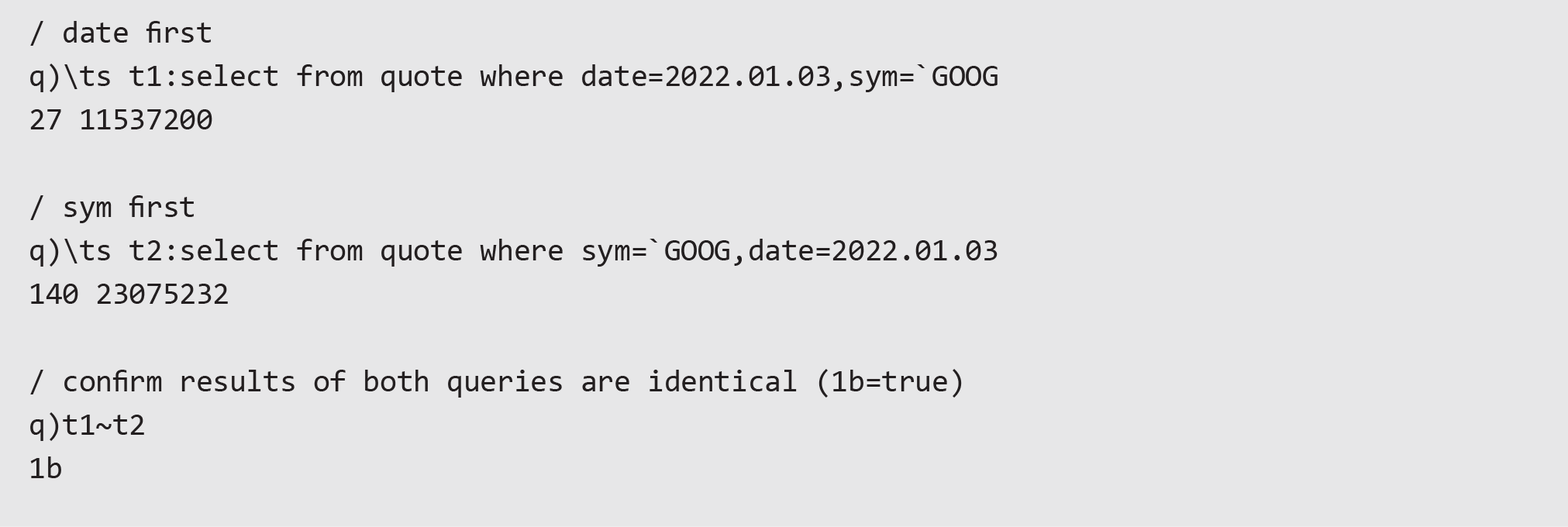
As can be seen in the example, both expressions obtain the same result, but placing the date first in the where phrase shows better performance. In the real world this difference will be magnified since databases are likely to cover thousands of dates spanning many years.
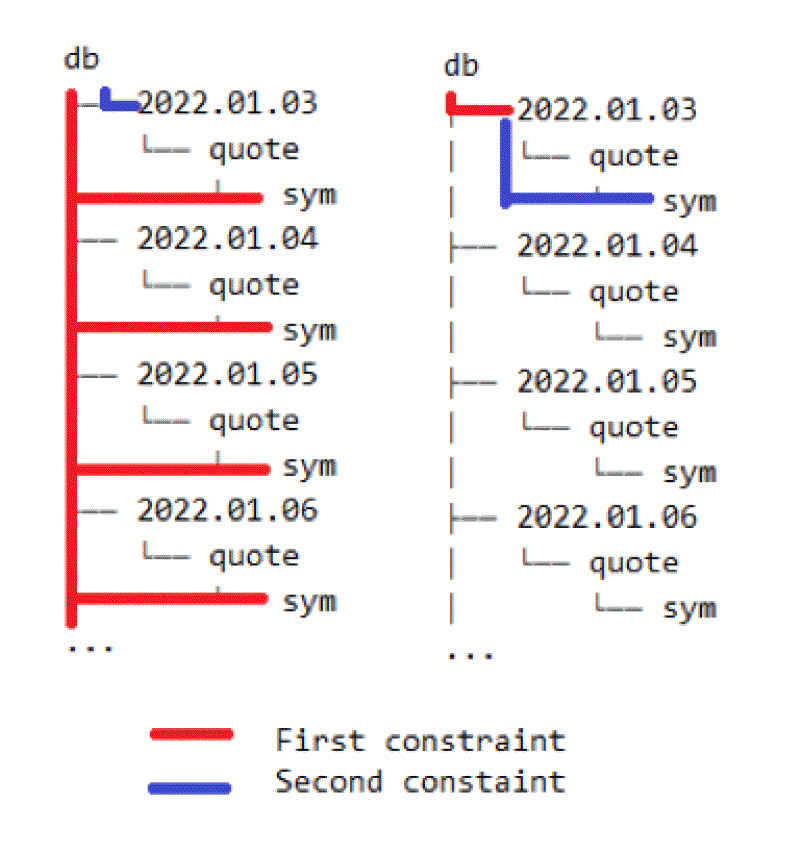
Similarly, when aggregating data, the partition column should also be used first in the by phrase to give better performance.

Attributes
Attributes are metadata that can be applied to lists in kdb+ to allow certain optimisations to be made when working with data. Since columns are lists, these optimisations will also apply to tables.
Typically for TAQ data on-disk, the parted attribute will be applied to the sym column, since this is one of the most frequently accessed columns. This can be confirmed by checking the metadata for a table using the meta keyword, which shows column names (c), datatypes (t), foreign keys (f), and attributes (a).

In the following example trade data is brought into memory (tr) and the parted attribute is deliberately removed (trn) so that query performance can be compared.

With the parted attribute applied, query performance when accessing the column sym is massively improved.
One caveat is that if constraining the attribute column with a list of values (for example, using the keyword in), the attribute only gives a boost for the first item in the list. To boost performance for all values, a lambda can be constructed so that each value can be passed in separately and benefit from the attribute. This can lead to reduced execution time, even with the overhead of using raze to collapse the results into a single table.
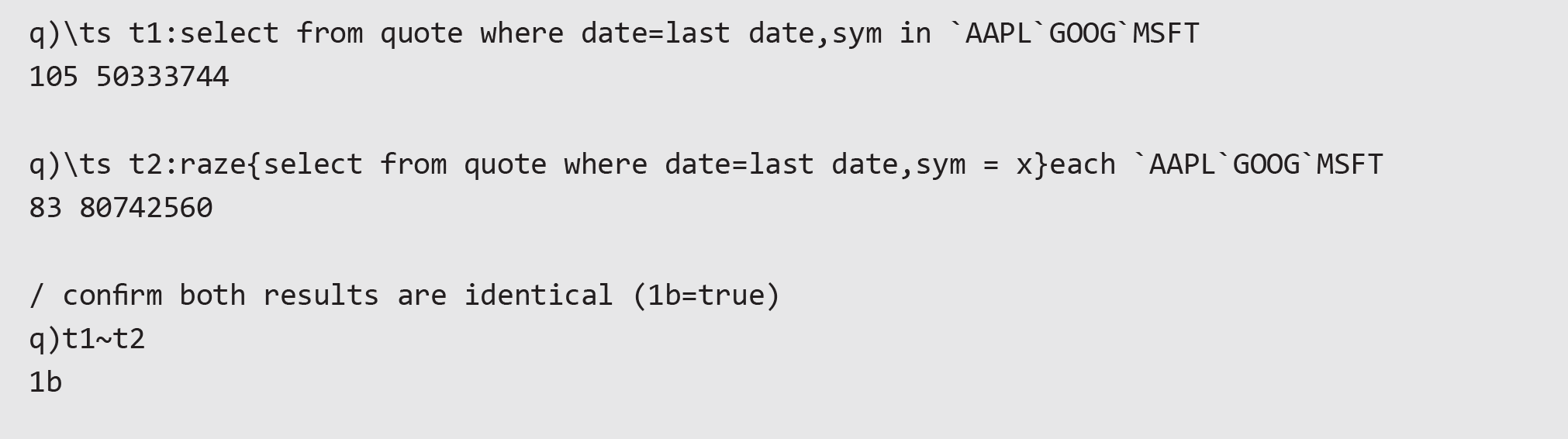
This improvement is not guaranteed and, in some circumstances, using a lambda will result in degraded performance.
It should be noted that the performance boost for attributes only applies if the attribute column is filtered first (or immediately following the partition column for partitioned data). If querying by other columns first, the attribute no longer applies to a subset of the original data, which can be seen below. As a result, performance may negatively impacted.

Ordering of Constraints
To further optimise queries, constraints should typically be organised from most to least restrictive—that is, those constraints that reduce the number of rows by the most to the least. In the following example filtering by size first gives a greater reduction than filtering by price. Ordering the constraints to filter by size first results in better performance.

Using Minimal Columns
By default, q selects all columns but selecting fewer columns will greatly reduce memory consumption. Query performance can therefore be improved by selecting only the necessary columns. When dealing with tables on-disk, only those columns referenced will be pulled into memory.

Selecting Subsets of Columns
For retrieving a subset of columns from non-partitioned tables, the take # operator is more performant than using a select statement. This can be seen from the example below using the trade data previously brought into memory (tr).

The drawbacks of using take # are that it does not work on partitioned tables, and it does not allow for where phrase filtering to be applied, so is useful only if selecting whole columns.
Counting Records
The kdb+ paradigm for counting rows in a table is to use the virtual index column i, which is present in all tables and can therefore be used when the schema is unknown. Virtual columns are created on demand when referenced and will degrade performance. It is recommended to instead reference a column present in the table, which requires knowledge of the schema beforehand.

Conclusion
The datasets used here are small relative to those seen in production systems, but the general principals apply at scale. Using poorly optimised queries on large datasets can introduce significant problems and may impact the system and users negatively.
The concepts presented in this article form a general guideline, and real-world performance will vary.
In summary, to optimise query performance users should apply the described concepts in the following priority order:
- When querying partitioned tables, filtering by the partition column should be done first.
- Columns with attributes applied should be filtered next.
- Remaining constraints should be ordered from most to least restrictive.
- Only select the columns necessary to complete the query.
- When counting rows in a table, use column names rather than the virtual i column.
Author
