This article looks at the importance of effective data management systems and their impact on risk management within banks. Data management is a set of processes and practices that determine how data is collected, organized, protected, governed, and stored in an organization to be effectively used to make sound business decisions.
Although multiple models outline the elements of an effective data management program (including DCAM, the Data Management Capabilities Assessment Model), the below diagram gets to the essence of the core elements to be considered:
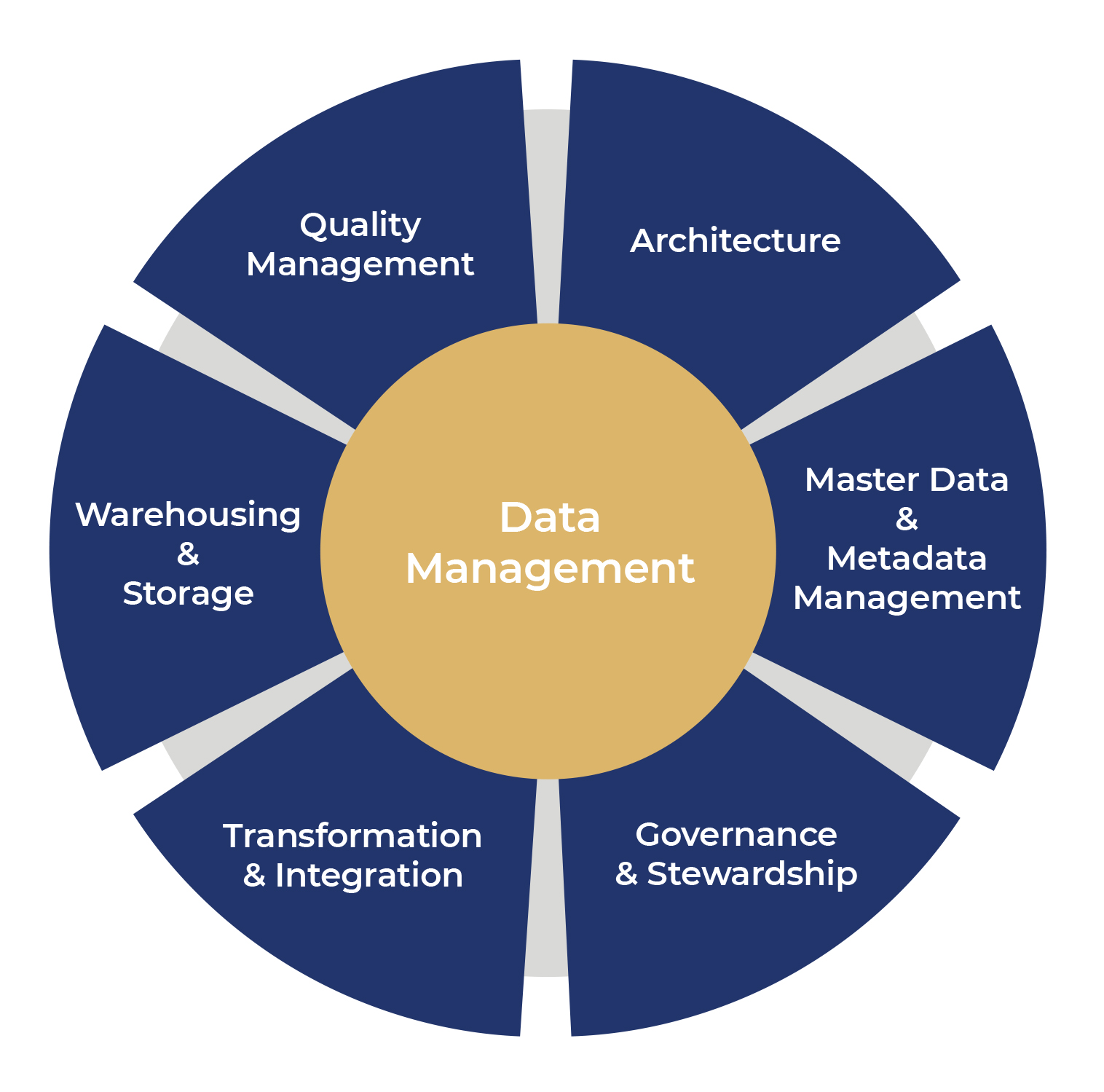
Most of these concepts are easy to understand in principle but can be tricky to implement in practice, especially if the organization does not have a dedicated data function in place. This is particularly true for some banks operating in the global markets, where incorrect or ineffective implementation of data management practices can have a major impact on a bank’s risk management capabilities.
Architecture
Data architecture defines how an organization’s data assets are documented, mapped, and transported through its IT systems. A well-thought-out data architecture ensures that the data strategy is business-driven, flexible, and scalable according to business demands, and secure with strong protocols to prevent unauthorized use.
Data modeling is an important element in determining the best data architecture. Based on the organization’s specific needs, the data architects must decide which data model should be implemented.
Normalized data models (in third normal form 3NF) might be the most efficient in terms of data modeling, but fully normalized data can be difficult to use consistently.
Entity Relationship models help remove data redundancies. An organization-wide common data model and centralized storage with strong governance to ensure compliance with the data model would ensure consistency in data across the business areas. However, the data architecture team must also understand the challenges faced by the organization and the rationale for having federated systems.
In an ideal scenario, data architecture would be the first step in the overall data management process, along with data modeling. However, this is not always the case, especially if the IT systems have evolved organically due to business reorganizations, mergers, acquisitions, etc.
One of the common problems when embedding data architecture principles is that data design in the existing operational systems is usually unable to keep pace with the changes demanded by the business. This can lead to short-term fixes and inconsistent data models that don’t cater to current business use cases. For regulatory reporting and risk management, this problem can be acute as existing systems are then forced to either utilize incomplete data by sourcing from non-standard sources or break the data design principles.
Another problem can occur when the data architecture does not consider all aspects of the business and is designed with a myopic view due to a lack of experience or complete requirements. One such scenario could be that the data is designed from the point of view of the trading systems, which might not always work for operations or back-office systems like risk management and finance.
Master Data and Metadata Management
Master data management is used to create a consistent set of data across different business units. It also defines a set of processes to consolidate, manage and distribute the master data. The primary focus of master data management is typically non-transactional and reference data. For banks, master data can take the form of customer data (internal and external), business line books and hierarchy data, tradable products data, instrument data (internal and external), and data related to any local regulatory bodies, etc.
While it is always prudent to get data from an authoritative source, it becomes absolutely vital for master data. In some cases, depending on the organization’s requirements, a bank’s trading systems might be federated based on location, business unit, or trading products. While this on its own doesn’t cause an issue, problems arise when there is no agreement between the systems on what the right source of master data should be, and there is no commitment from the multiple business units. When this occurs, each federated trading system tries to solve its problems by creating a localized reference data source that does not fit into the overall organizational architecture.
For global risk management systems, this inconsistency causes issues as the data from different sources can’t be effectively aggregated for risk reporting. For example, a trading entity in APAC might be maintaining their version of the hierarchy of the internal book, making it very difficult for the global risk management function to include these books in their aggregated reporting.
It is not enough that all master data is consistently sourced from the agreed and accepted golden source. It is also equally important to maintain the integrity and validity between different datasets. More often than not, banks would maintain the master data in silos and leave it up to the downstream systems (i.e., risk and finance) to link the datasets together. Any potential mismatch then becomes the responsibility of these downstream system to fix. For example, suppose a bank has the correct, consistent source for client and entity data and the correct source for instrument data, but the two data sets are not properly linked with a common/valid identifier. This might impact the bank’s ability to properly calculate issuer risk and effectively identify wrong way risk. Similarly, the impact on risk-weighted assets (RWA) from improperly linked market data can be significant.
Governance and Stewardship
Governance relates to the definition of the different processes, policies, rules, and procedures used to regulate the organization’s data. The data governance process must ensure a common, clear, unambiguous definition for each of the data elements and ensure they are adhered to. Data governance works best when there is input from all business units and an agreed definition of best practices.
Data stewardship is an important element of governance as it manages and oversees the implementation of these rules and policies. Data governance policies are of no use if not implemented correctly. While this can be obvious for some types of data in a bank, identification, assignment, and acceptance of data ownership is not always a straightforward task. If no clear data owner is identified for each data domain, banks can find themselves in a situation where multiple data owners or the ownership defaults to the IT department. Lack of clear ownership could lead to unclear policy definition or improper implementation of existing policies, putting into question the data quality. This puts further responsibility on the risk management function to ascertain the quality of the data they don’t own with no recourse to appropriate escalation if issues are found.
Transformation and Integration
Before data can be made available for business decisions and management information, it needs to be sourced from the appropriate source system, transformed into a meaningful data model, and stored for access. Data transformations and integration link the data architecture and data models with data storage. If the transformation and integrations are not correctly implemented, there is a risk of information loss when the data gets to the warehouse. One method to ensure correct implementation is to assign data stewards in each function and make them responsible for the data flows in their systems. This can then be managed via a central data office.
It is vital that all relevant sources of data are integrated to ensure completeness. Any missed source that is not integrated with the central data warehouse can cause incorrect reporting, especially at the group level. For example, banks could focus on integrating trading data from their major operations hubs. Some smaller sites with fewer trades, however, might not be included when designing data integration. Integrations that miss or ignore this information would not be considering all the data for group level regulatory reporting.
Data design and data models that don’t consider real life data scenarios can cause significant problems during data integration. The disconnect between the logical data models defined at the enterprise level and the transformations of the physical data can be problematic when demonstrating data lineage. All the data governance processes and procedures defined based on the data architecture would not be applied to the physical data. The BCBS 239 principle of proving data lineage from the originating system to risk control reporting can be inaccurate if the data transformations are not implemented correctly.
Warehousing and Storage
Big organizations process large volumes of data that must be stored for use by the business. How the data is stored and what data warehousing solutions are used is a critical part of data management. Regardless of the underlying technology used – on-premises storage or external cloud storage – careful consideration should be given to the design of the data warehouse.
Although most banks focus on effective data storage while designing the data warehouse, one aspect that is sometimes overlooked is how will the consuming systems access the data and what consumption patterns are supported by the data warehouse? Getting this wrong might impact scalability. Further, data warehouse implementations are usually done under intense time pressure, leading to incomplete design.
For example, it might be easier not to store the buy/sell indicator on a trade as it can be determined from the notional value, type of trade, counterparty information, etc. If a common, consistent consumption pattern is not provided for such data sets, then each of the downstream consuming systems (market risk or counterparty credit risk) will need to derive this value independently, introducing inefficiencies in the system.
Data storage must also consider future data volume demands and access requirements, especially for new regulations like FRTB IMA. Any data warehouse designed with only current data volumes in mind may not be scalable or efficient when the volumes go up.
Data Quality Management
Data quality management consists of processes and controls to measure data quality within the organization. The requirements of BCBS 239 have placed a heavy focus on data quality improvement for risk data aggregation and control reporting. Some of the criteria used to measure data quality are accuracy, validity, completeness, timeliness, and reasonableness. Model governance can also be achieved via proper data controls.
Data quality management should support a front-to-back view of the data quality within the organization. In our experience, individual departments within the bank will often implement specific controls on the data they own but won’t share the data quality metrics outside of their department. This leads to redundant data controls, multiple reconciliations, and a lack of transparency between different functions. One way to address this is to centralize data quality and control within the bank. While the actual data ownership is retained by the respective businesses, a set of agreed data control tests could be performed by an independent controls department and made available to all producing and consuming systems.
For example, if the trading systems are reconciling their end-of-day live trades with the operational data store but are not sharing the result of the reconciliation with the risk system, the completeness of the data would be in question, resulting in risk reporting on an incomplete dataset. A central controls function can perform the reconciliation for all systems (trading systems, risk, and finance), reducing the total number of reconciliations in the bank.
Additionally, by linking the data quality metrics back to the data to which it relates, all the consuming systems will have the same view of the data quality. Consistency of data quality also promotes data alignment across back-office systems like risk and finance, which is key for FRTB back-testing and P&L attribution testing.
Conclusion
Risk management and reporting is usually the recipient of data from upstream and is also the confluence point of different types of data such as transactional data, market data, reference data, and risk and valuation data. As such, the impacts of any inefficiencies in any part of data architecture or any omissions in data quality controls could have a compounding effect on a bank’s risk management and even on capital and RWA calculations.
Effective data management practices are a fine balance between trying to cater to strategic business data needs, ensuring appropriate governance and control, and being practical and applicable to be implemented effectively. At Vox, now part of Treliant, our SME team has the right level of experience, expertise, and maturity to help you streamline your data. To find out more, please contact phil.marsden@voxfp.com.
Written by: Paresh Dhoke, Principal Consultant